
本文是《提升你的 Python 项目代码健壮性和性能》系列的第 3 篇文章。
本系列总计 8 篇文章目录
- 用 Type Annotation 提升你的 Python 代码健壮性
- 如何通过测试提升 Python 代码的健壮性
- 如何保证 Django 项目的数据一致性
- 这几招,让你快速提升 Python 项目的性能
- 为你的项目快速搭建 ELKFA 日志系统
- 如何写出整洁的 Python 代码 上
- 如何写出整洁的 Python 代码 中
- 如何写出整洁的 Python 代码 下
0x00 前言
这次我们来谈谈 Django 项目并发可能带来的问题以及如何保持 Django 项目的数据一致性。
本文目录如下:
0x00 前言 : section
▼ 0x01 背景知识 : section
并发会带来数据不一致 : section
▼ 0x02 Django 项目如何解决项目 : section
悲观的方式 : section
乐观的方式 : section
没有银弹 : section
0x03 解决超卖问题 : section
▼ 0x04 番外篇 数据库隔离级别 : section
READ-UNCOMMITTED : section
READ-COMMITTED : section
REPEATABLE-READ : section
SERIALIZABLE : section
0xEE 参考链接 : section本文讨论的场景如下:
一个简单的秒杀系统,商品还剩 200 件。有一些用户来访问并下单。
这个项目的接口的简单写法就是:
@db_transaction
def user_order_by_product(user,product):
if product.quantity > 0:
product.quantity = product.quantity - 1
make_order(user,product)
product.save()显然,这个写法确实简洁。
但问题就来了。
商品会超卖, 除非你的应用没什么人访问。
为什么呢?
0x01 背景知识
并发会带来数据不一致
看图
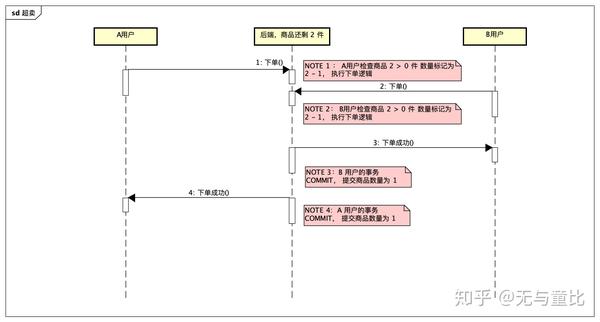
知道问题出在哪儿了吧?
- 理解了?
- 你确定理解了?
- 你确定你真的理解了?

其实是我给读者挖了一个坑,我画的这张图其实是有预设的,比如 NOTE2 处确保了 B 用户读到的是 2。
如果数据库隔离级别是 read uncommitted, NOTE2 处读到的也有可能是 1 ,
本文仅仅针对于 read committed 隔离级别下的 MYSQL / PostgreSQL。
在上图中。
一般人写程序
- 往往不是用 Django 的 F 表达式,来实现 update balance = balance - 20 的操作。 update balance = balance - 20 where id = 1
- 而是计算 出新的 balance 然后 user.balance = 80, 接着 user.save()
这就会放大了问题
在低并发量的情况下,这个用户手动不断的下单,下单到 200 的时候,后端准时的报卖完了。
假如我现在是 20 个用户同时在下单,很可能机会出现上图的情况。
出了问题要解决问题 看到问题就要想法子
- 鲁迅说过,一见短袖子,立刻想到白臂膊,立刻想到全 X 体,立刻想到....
- 我也说过,提到并发,就想到锁,就想到乐观锁,就想到悲观锁。
0x02 Django 项目如何解决项目
有乐观的方式和悲观的方式,即所谓的乐观锁和悲观锁。是不是有高下之分呢、? 不一定。
这就好比乐观和悲观本身也并不见的有高下之分。如同有的人乐观,并不见得一定就是乐观,搞不好是傻乐呵,有的人的悲观,只是底色比较悲凉,但内心还是积极向上的。
本小节内容依照自己的理解厚颜无耻的援引了这篇文章的代码
https://medium.com/@hakibenita/how-to-manage-concurrency-in-django-models-b240fed4ee2
悲观的方式
悲观的方式就是锁住某个资源,不让其他人使用(排他),直到完成工作后释放。
为什么使用数据库的锁(准确来说是关系型数据库的锁)
- 数据库非常擅长处理锁来完成数据一致性。
- 数据库级别的锁可以保护其他进程修改数据。
@classmethod
def deposit(cls, id, amount):
with transaction.atomic():
account = (
cls.objects
.select_for_update()
.get(id=id)
)
account.balance += amount
account.save()
return account
@classmethod
def withdraw(cls, id, amount):
with transaction.atomic():
account = (
cls.objects
.select_for_update()
.get(id=id)
)
if account.balance < amount:
raise errors.InsufficentFunds()
account.balance -= amount
account.save()
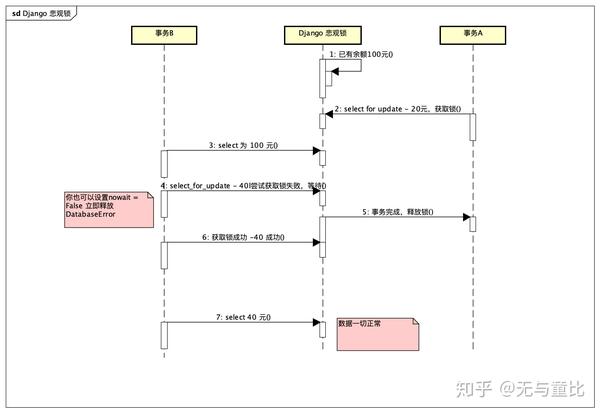
return account使用 select_for_update 锁住这个 object 直到事务结束
在使用悲观锁的情况下,存钱和取钱流程如下
乐观的方式
乐观的方式就是新建一个 version column, 每次修改余额的时候,版本增 1
同样我厚颜无耻的援引了 hakibenita 的代码
def deposit(self, id, amount):
updated = Account.objects.filter(
id=self.id,
version=self.version,
).update(
balance=balance + amount,
version=self.version + 1,
)
return updated > 0
def withdraw(self, id, amount):
if self.balance < amount:
raise errors.InsufficentFunds()
updated = Account.objects.filter(
id=self.id,
version=self.version,
).update(
balance=balance - amount,
version=self.version + 1,
)
return updated > 0django 默认会返回修改成功的行数,于是,是不是存取成功,就看 updated 是否大于 0 了
没有银弹
计算机世界里面,多快好省的场景就不存在。一切看场景。
同样在并发量大的情况下
1. 如果对某几行修改比较频繁,版本更新频繁,可能乐观锁的 retry 就比较浪费了。 2. 如果是对整张表的更新比较频繁,而不是频繁修改某几行。乐观锁,就比较合适了。
- 乐观方式在应用层,无法阻拦数据库的操作。不会存在死锁的问题。
- 悲观方式是数据库实现,他阻止数据库写操作。
0x03 如何解决超卖问题
- 把数量和已卖放到 redis 里面呢?
- 交给 deamon 呢?
- 用 celery 然后排个队异步任务呢?
搞个再复杂一点点的,
- 在 Redis 里面直接生成 200 个订单号
- 然后用户来一个取走一个订单号码
- 通过 Celery 削峰 排队走异步任务
- 最后通过数据表的 uniq 约束来防止下单超过 200 个。
嗯,就是这么简单。
0x04 番外篇 数据库隔离级别
提到了数据库隔离级别,就利用上面的例子顺手讲解一下数据库隔离级别吧。
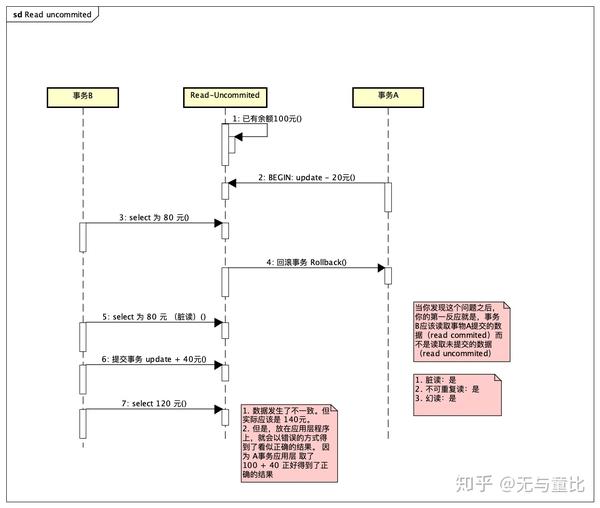
READ-UNCOMMITTED
READ-COMMITTED

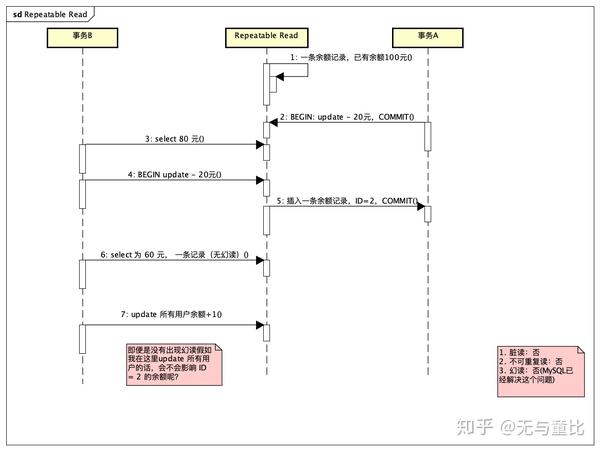
REPEATABLE-READ
SERIALIZABLE
这个就不放图了。没啥好讲的。性能太低.... 我是基本上没怎么使用过的
性能上 RU > RC > RR > S
一般人用 RC 和 RR 会多一些,比如我的项目里就使用了 RC , 但什么时候我可能会考虑用 RR 呢、? 比如,我想在一个 Session 里面选两次 最近两个月的用户数据,但是并不希望 出现新的用户。
0x05 番外篇 Django ORM
评论区
提出了防止超卖的另一种解决方案
# 先做订单记录,在直接 sql 改数量,前提库存大于 0,失败一个就事务回滚,抢购失败。即
def do_order(product):
with transaction.atomic():
order = make_order(product)
# 他的思路 是 RawSQL
# updated = sqlexecute(f"update from product set quantity = quantity - 1 where id = {product.id} and quantity > 0 ")
# 在这个基础上,其实可以写出 django orm 对应的语句
updated = Product.objects.filter(
id=id,
quantity_gt=0
).update(
quantity=quantity - 1,
)
if updated == 0:
transaction.rollback()面向业务设计的表,和面向数据分析的表应该是两种设计思路。orm 是实体和记录的映射,比较适合面向业务设计的表。
也提到表关联查询太痛苦了
在我的认知里
- Django 本身是支持 RawSQL 查询的
- 当你想要的 object 和 row 是一一对应关系的时候,ORM 写起来特别舒服
- django orm 写过滤条件是很舒服的。(抛开性能来说)
- 针对 Object 的修改也很方便,比如商品数量减少。比如自增 update。这也是 orm 的不足之处,显式多表连续 join 的话过滤条件就很麻烦。
如果需要关联查询这也应该看情况
- 如果一般的多表连续 join 如果能使用 nested queries 的话,用 Django 写起来也是特别的舒服。(如果你不是使用 mysql 这种对 nested query 几乎无优化的数据库)
VoteActivity.objects.filter\(category=obj.category, user\_\_name\_contains\("王"\), user\_\_city\_\_type="一线城市"\) # 伪代码2. 或许是应该走 ETL 或者是把数据丢到 ES 或者针对查询优化的表会更加合适、?
当然,这也就看具体的情况了。